
Comment faire bonne impression en disant bonjour ?
Numérique
Un bonjour optimal, ça s'entend et maintenant ça se voit. Des chercheurs du CNRS, de l'ENS et d'Aix-Marseille université 1 ont établi une méthodologie expérimentale leur permettant de révéler avec quel « filtre » (ou représentation mentale) nous jugeons la personnalité de quelqu'un à l'écoute d'un mot aussi simple que « bonjour ». Quelle intonation est optimale pour donner l'impression d'être déterminé ou digne de confiance ? Cette méthode, déjà utilisée par les chercheurs à des fins cliniques notamment auprès de personnes ayant subi un AVC, ouvre désormais un grand nombre de pistes dans la perception du langage. Ces résultats sont publiés dans la revue PNAS le 26 mars 2018.
- 1AU SEIN DU LABORATOIRE SCIENCES ET TECHNOLOGIES DE LA MUSIQUE ET DU SON (CNRS/IRCAM/MINISTÈRE DE LA CULTURE/SORBONNE UNIVERSITÉ), DU LABORATOIRE DES SYSTÈMES PERCEPTIFS (CNRS/ENS PARIS) ET DE L'INSTITUT DE NEUROSCIENCES DE LA TIMONE (CNRS/AIX-MARSEILLE UNIVERSITÉ).
Lorsqu'un inconnu vous dit « bonjour », vous paraît-il amical ou au contraire hostile ? L'intonation vocale, est à la base des jugements linguistiques et sociaux dans le discours. De la même façon que nous avons une image mentale d'une pomme (ronde, verte ou rouge, avec une queue…), nous possédons également des représentations mentales de la personnalité de quelqu'un à partir des paramètres acoustiques de sa voix. Pour la première fois, des chercheurs sont parvenus à visualiser ces représentations mentales et à les comparer entre individus.
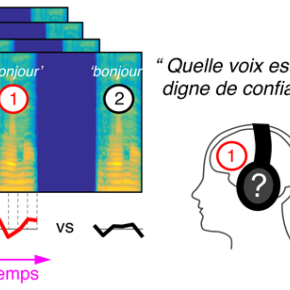
Pour cela, les scientifiques ont mis au point une technique informatique de manipulation de la voix : le logiciel CLEESE. À partir de l'enregistrement d'un seul mot, ils génèrent aléatoirement des milliers d'autres prononciations du même mot ayant toutes une mélodie différente tout en gardant un ton réaliste (une sorte de maquillage sonore). En analysant les réponses des participants à ces enregistrements manipulés, les chercheurs ont caractérisé expérimentalement l'intonation du « bonjour » sincère. Par exemple, pour paraître déterminé le mot doit être prononcé avec une hauteur descendante, plus marquée sur la deuxième syllabe ![]() /
/ ![]() . Au contraire, pour être perçu comme digne de confiance, la hauteur doit monter rapidement à la fin du mot
. Au contraire, pour être perçu comme digne de confiance, la hauteur doit monter rapidement à la fin du mot ![]() /
/ ![]() . Les chercheurs sont donc désormais capables de visualiser le « code » utilisé par les gens pour juger de la voix d'autrui, et ont montré que ce code est partagé par les hommes comme par les femmes et est indépendant du sexe de la voix écoutée.
. Les chercheurs sont donc désormais capables de visualiser le « code » utilisé par les gens pour juger de la voix d'autrui, et ont montré que ce code est partagé par les hommes comme par les femmes et est indépendant du sexe de la voix écoutée.
Cette méthode peut s'appliquer à un grand nombre de questions dans le champ de la perception du langage. Comment ces résultats s'étendent-ils à une phrase entière ? Les représentations mentales dépendent-elles de la langue parlée ? Elle pourrait aussi s'appliquer à identifier la représentation des émotions notamment auprès de personnes souffrant d'autisme. Afin de répondre à ces questions, les chercheurs mettent leur logiciel CLEESE à la disposition de tous (disponible ici). Pour sa part, l'équipe de recherche à l'origine de l'étude présentée ici, l'utilise déjà à des fins cliniques, notamment pour analyser la perception des mots auprès de personnes victimes d'un AVC, une pathologie qui peut altérer la perception de l'intonation de la voix. Que ce soit à des fins de suivi thérapeutique ou encore de diagnostic, ils souhaiteraient l'utiliser pour la détection d'anomalies de la perception du langage et peut-être même en faire un outil d'aide à la rééducation.
Découvrez également le reportage vidéo "Dis moi "bonjour" et je te dirais qui tu es" sur le site de CNRS le journal.
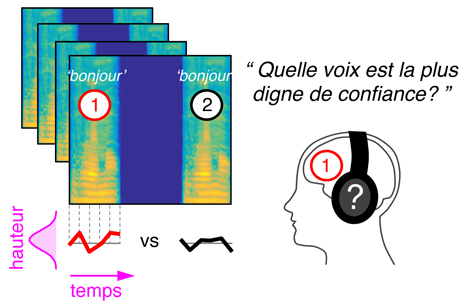
Méthodologie utilisée pour accéder aux « représentations mentales » de l'intonation dans la voix. Les participants jugent l'intonation d'un grand nombre de « bonjours » générés algorithmiquement et déterminent celui qui leur paraît « digne de confiance » par exemple. L'analyse de milliers de réponses permet de visualiser les représentations mentales auditives de chaque individu.
Bibliography
Cracking the social code of speech prosody using reverse correlation. Emmanuel Ponsot, Juan José Burred, Pascal Belin & Jean-Julien Aucouturier, PNAS, 26 mars 2018. DOI : 10.1073/pnas.1716090115
Contact
Emmanuel Ponsot
ENS researcher
Pascal Belin
Aix-Marseille Université researcher
Anaïs Culot
CNRS press office

