Un nouveau mécanisme pour les différences inter-individuelles d’apprentissage
Tous les individus n’attribuent pas de la même manière une valeur motivationnelle aux objets de leur environnement. Certains sont attirés vers un stimulus, d’autres vers la récompense associée à ce stimulus. Ces comportements correspondent à des signaux différents dans les neurones dopaminergiques du tronc cérébral. A partir des prédictions d’un modèle computationnel, une équipe franco-américaine vient de caractériser expérimentalement les mécanismes de ces différences inter-individuelles. Cette étude a été publiée dans la revue PLOS Biology.
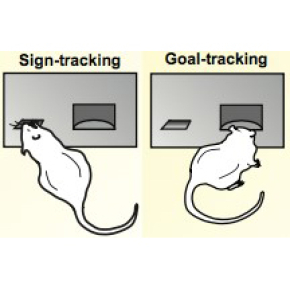
Apprendre la valeur des objets et événements de notre environnement est une fonction essentielle à la survie. Un stimulus associé à une récompense acquiert une valeur motivationnelle chez certains individus, dits « sign-trackers ». Chez l’humain, les individus sign-trackers pourraient être plus sensibles aux stimuli et contextes associés à une prise de drogue et vulnérables à la rechute après sevrage. Comprendre l’origine de ces différences inter-individuelles peut donc avoir des impacts importants en matière de santé publique.
Par opposition aux sign-trackers, des animaux goal-trackers se désintéressent du stimulus conditionné lui-même et apprennent selon des principes différents. Chez les sign-trackers, les réponses des neurones dopaminergiques ont les caractéristiques attendues de signaux d’erreur de prédiction (reward prediction error, RPE): en début d'apprentissage elles correspondent à des récompenses inattendues (erreur de prédiction positive), puis diminuent lorsque la récompense devient prévisible (erreur de prédiction nulle). Mais chez les goal-trackers ces réponses persistent alors même que la récompense est parfaitement prévisible, et leur apprentissage semble indépendant de la dopamine.
Afin d’expliquer ces différences comportementales et neurobiologiques, les chercheurs ont récemment proposé un modèle computationnel "STGT" (pour sign-trackers / goal-trackers) qui repose sur l’équilibre entre deux formes d’apprentissage, l’une appelée model-free dépendante de la RPE et l’autre appelée model-based, plus flexible, qui permet une anticipation explicite des événements et des actions. Seul le premier de ces deux systèmes est supposé dépendre de la dopamine. La valeur calculée par les deux systèmes serait combinée sous la forme d’une somme pondérée. Différents individus pourraient donc utiliser davantage l'un des deux apprentissages plutôt que l'autre, et attribuer ainsi des valeurs indépendantes au levier et à la mangeoire (Figure 1).
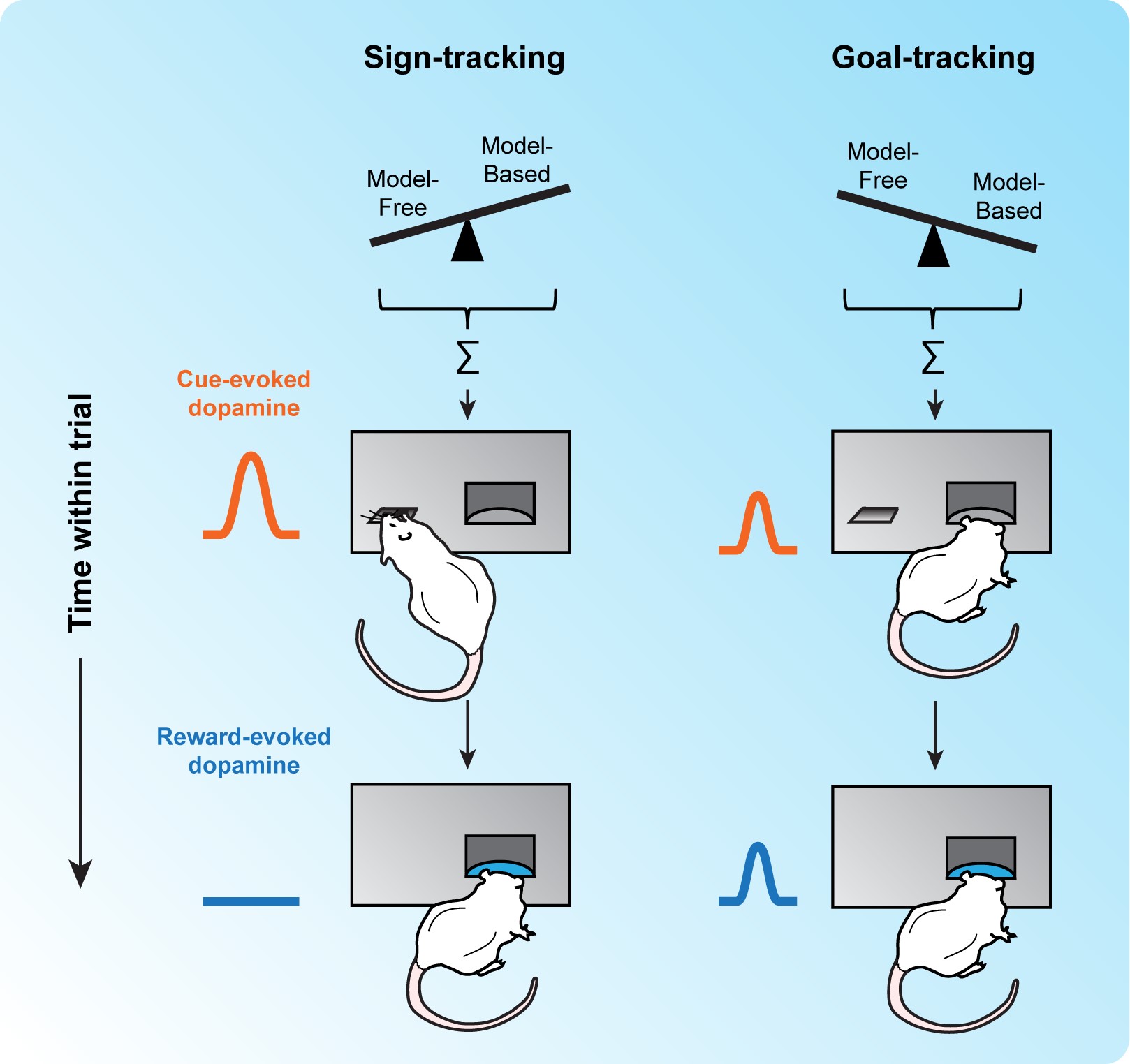
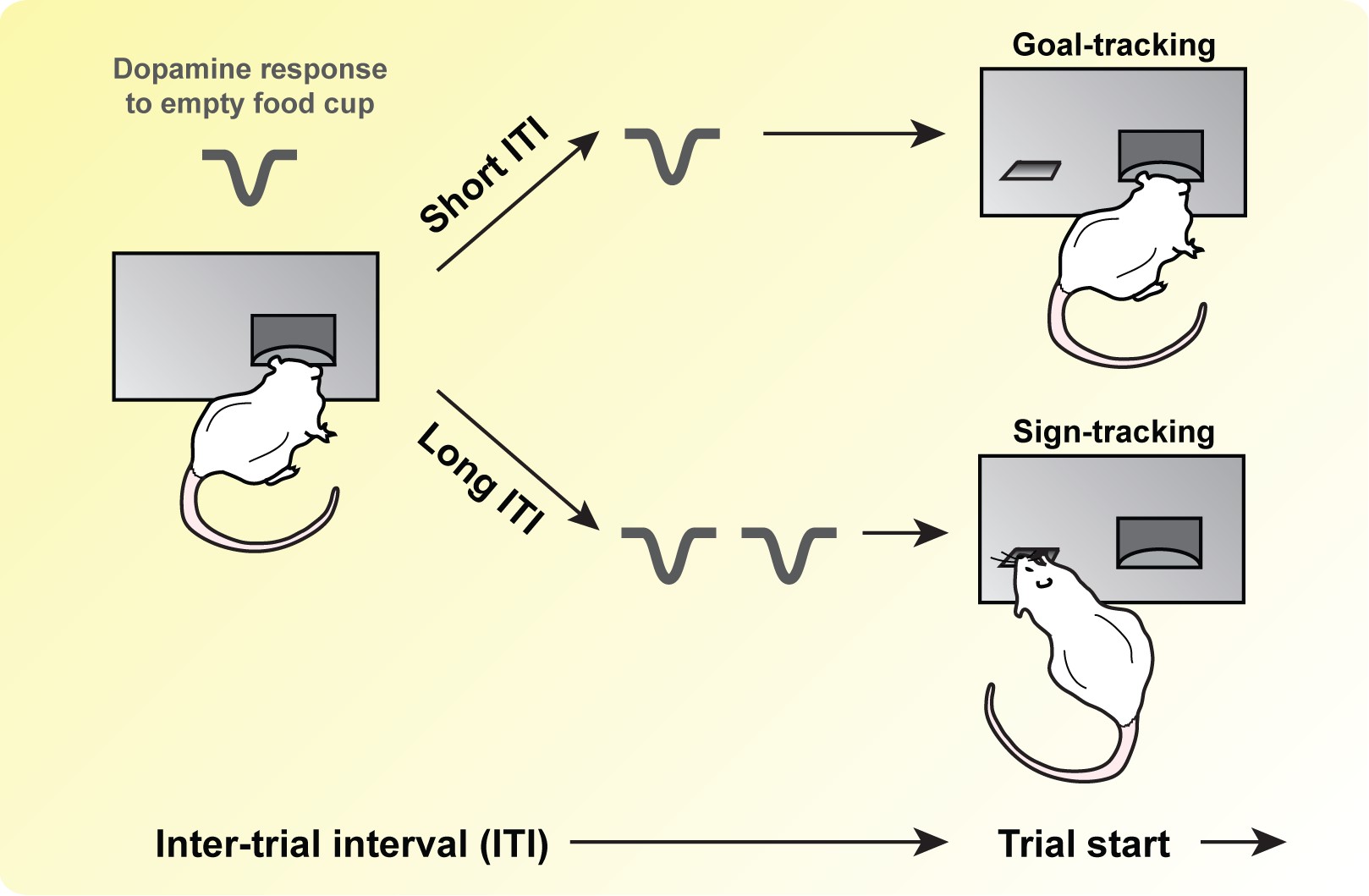
Le modèle STGT prédit toutefois que les différences inter-individuelles d’apprentissage ne soient pas absolues, puisque des manipulations paramétriques de la tâche pourraient modifier la manière dont les individus attribuent une valeur prédictive aux stimuli de l'environnement. Le modèle prédit ainsi qu’il suffit d’augmenter l’intervalle entre les essais (intertrial interval, ITI) pour faire apparaître dans la population une plus grande proportion de comportements de type sign-tracker et de signaux dopaminergiques de type RPE. A l'inverse, un ITI plus court induirait une plus grande proportion de comportements de type goal-tracker et des signaux dopaminergiques ressemblant moins à une RPE (Figure 2).
© Eshel & Steinberg (2018) PLOS Biology, Creative Commons Attribution (CC BY)
Afin de tester ce modèle, une collaboration interdisciplinaire franco-américaine a été menée entre des scientifiques de l’Institut des Systèmes Intelligents et de Robotique (ISIR, CNRS/Sorbonne Université), de l’Institut de neurosciences cognitives et intégratives d’Aquitaine (INCIA, CNRS/Université de Bordeaux) et le Département de Psychologie de l’Université du Maryland.
Cette étude a pour but de tester directement les prédictions du modèle concernant l’effet de l’intervalle inter-essais sur le comportement et l’activité dopaminergique. Dans la tâche proposée, des rats sont soumis à un conditionnement Pavlovien par lequel un stimulus (la présentation d’un levier) est suivi invariablement après 8 secondes par une distribution de nourriture dans une mangeoire. Comme observé précédemment, les individus sign-trackers s’intéressent au levier alors que individus goal-trackers se concentrent sur la mangeoire. Par une approche de voltamétrie à cycle rapide, les chercheurs ont enregistré les variations rapides de l'activité dopaminergique dans cette tâche pour différentes durées de l'ITI.
Les résultats obtenus ont permis de confirmer les prédictions principales du modèle en montrant que la proportion de comportements de type sign-tracker augmente avec l’ITI, et que cette augmentation est associée à une activité dopaminergique de type RPE. De plus, les animaux montrent souvent des réponses alternant entre le levier et la mangeoire. Ces résultats sont en accord avec l’idée que tous les individus sont potentiellement susceptibles d’exprimer les deux types d’apprentissage en fonction des contraintes de l’environnement. Ils soulèvent de nouvelles questions concernant le support nerveux des apprentissages model-free et model-based, leur relation avec le signal RPE, et leur lien avec des pathologies telles que l’addiction ou les troubles obsessionnels-compulsifs.
© Eshel & Steinberg (2018) PLOS Biology, Creative Commons Attribution (CC BY)
Pour en savoir plus :
Manipulating the revision of reward value during the intertrial interval increases sign tracking and dopamine release.
Lee B, Gentry RN, Bissonette GB, Herman RJ, Mallon JJ, Bryden DW, Calu DJ, Schoenbaum G, Coutureau E, Marchand AR, Khamassi M, Roesch MR.
PLoS Biol. 2018 Sep 26;16(9):e2004015. doi: 10.1371/journal.pbio.2004015. eCollection 2018 Sep