

Actualité
Le CNRS parmi les premiers bénéficiaires des Chaires d’excellence en biologie-santé

Actualité
Laboratoires communs : quand science et entreprises se rencontrent

Actualité
Entretien exclusif avec Iliana Ivanova sur l’avenir de la recherche européenne
Toutes nos
actualités
Toutes nos
actualités
actualités


Le Journal
Mécanobiologie : la pression créatrice
Développement d’un embryon, métastases... de nombreux phénomènes cellulaires sont guidés par des forces mécaniques. Ces dernières font l’objet d…
Découvrir
Presse
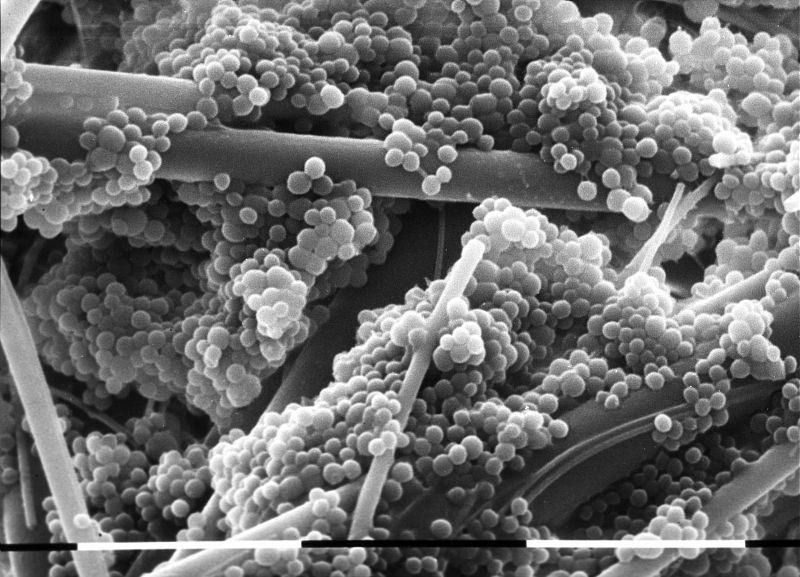
Découverte d’un mécanisme de survie du staphylocoque doré dans le sang
Le staphylocoque doré est l’une des principales causes d’infection bactérienne en France et dans le monde, responsable notamment d’infections…
Découvrir
Zoom sur...
Zoom sur...






